对于很多机器学习和深度学习的初学者来说,数字识别是一个非常棒的学习和练手项目。我将在这篇文章中介绍搭建一个识别印刷体数字的分类器的思路和方法并附上完整可运行的代码。
这是一个识别印刷体数字的分类器,我们输入的是一张含有数字的图片,经过分类器的分析处理,我们能够框出图片上的数字并识别。比如这样:

当功能确定以后,我们就需要为分类器设计一个神经网络模型,寻找一个合适的数据集对模型进行训练,然后验证模型的准确性,最后我们还可以在各种平台应用这个模型。
在这个问题中,我们使用的是简单的多层神经网络,结构如下图:
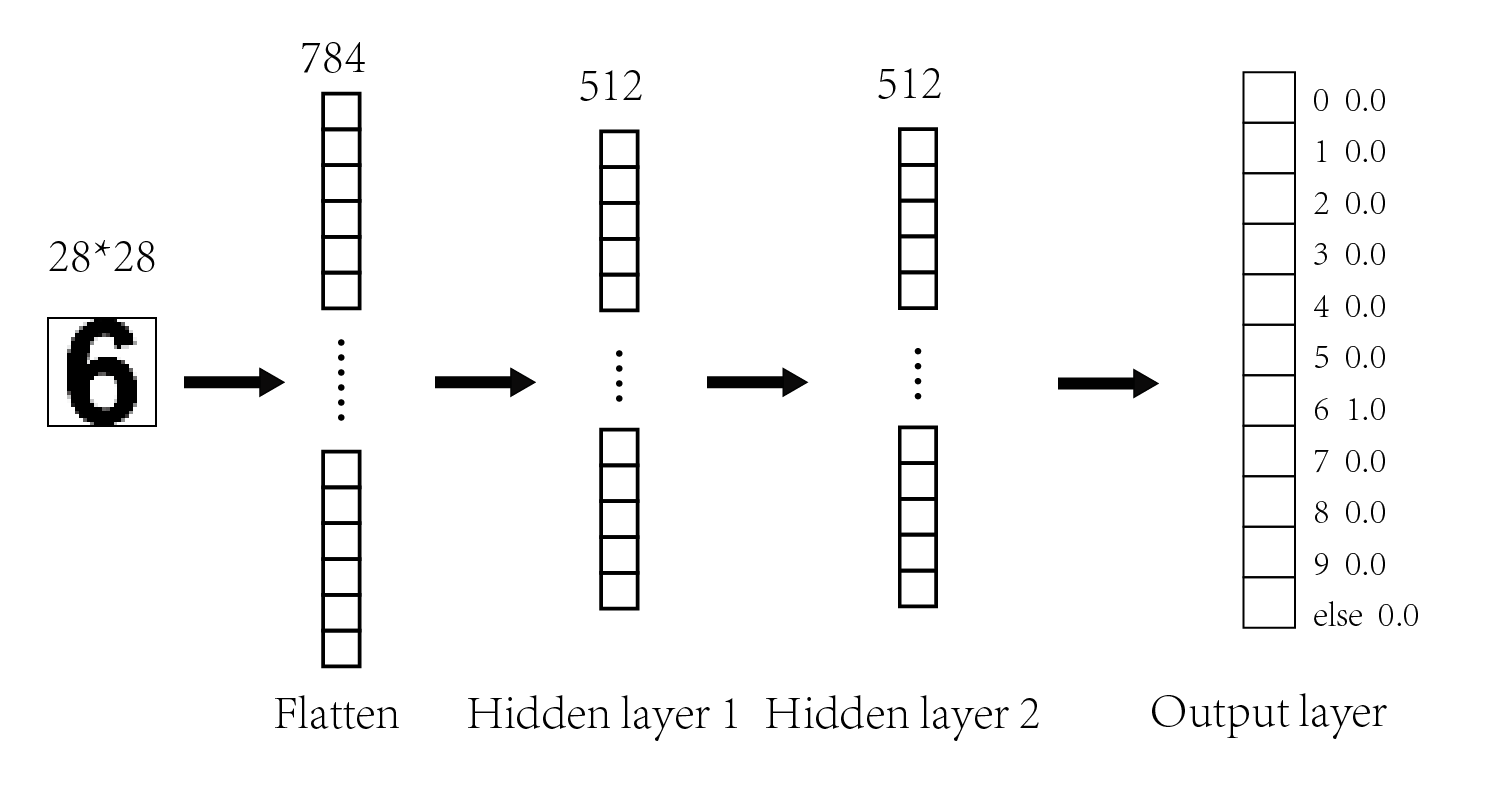
我们对其输入的是一个 28*28 的图片,经过 flatten 转换成784个数据点作为输入。这个模型含有两个隐藏层,每个隐藏层有512个神经元。784个数据点输入以后,经过两个隐藏层运算后就输出成了11个类的概率。这11个类包含0~9十个数字和一个非数字类,概率最大的那个就是我们的预测结果。
1.数据集的选择和预处理
我们选择的数据集来自英国萨里大学的网站。这个网站提供了多种英文字母数字的数据集,有来自生活场景的,也有电脑印刷体的。我们选择的是EnglishFnt.tgz,这个数据集包含了印刷体数字和字母的60000+的样本。

在这个项目中,我们选择了用程序自动下载和自动解压的方法,这个过程也可以手动完成。
在这里强烈给大家推荐tqdm这个库,tqdm 是阿拉伯语,意为“进度”。使用这个库我们可以在下载,处理以及训练等需要耗费较多时间的程序中加入进度条,直观的看到需要花费的时间以及进度。
大家可以去解压后的目录 /English/Fnt/ 下查看解压后的数据集,由于数据集中包含 0~9 10个数字 以及 A~Z 26个字母的大小写,所以会有Sample001~Sample062,共62个文件夹。

数据集中包含 0~9 十个数字 以及 A~Z 26个字母的大小写,但是我们最后的分类器会分11个类,0~9 每个数字一类以及一个非数字类。非数字类就是 A~Z 26个字母的大小写,我们需要将这些文件移到同一个文件夹中。在这里,我们将 A~Z, a~z 的图片移到 Sample011 中,再将其他空文件夹删除。
2.数据集中图片的预处理
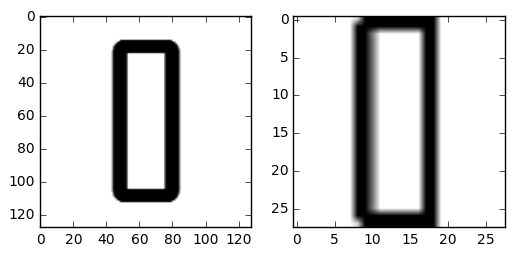
对于图片的预处理过程取决于我们采用的模型,在这个项目中,我们模型的输入是28*28的灰度图片。于是,我们把这两个步骤写成了两个函数,使用resize(rawimg)来调整图片大小,使用convert(imgpath)将图片调成灰度。
3.分离验证集
分离验证集的时候,我们使用的是机器学习库sklearn的train
_test_split,将数据集中90%的内容作为训练集,10%的内容作为验证集。
4.图片生成器
在进行训练的时候,由于训练集往往会包含几万张图,所以我们通常不会选择将所有训练集的图片加载到内存当中而是选择使用图片生成器ImageDataGenerator。使用图片生成器生成一个batch的图像数据,支持实时数据提升。训练时该函数会无限生成数据,直到达到规定的epoch次数为止。
5.模型搭建和训练
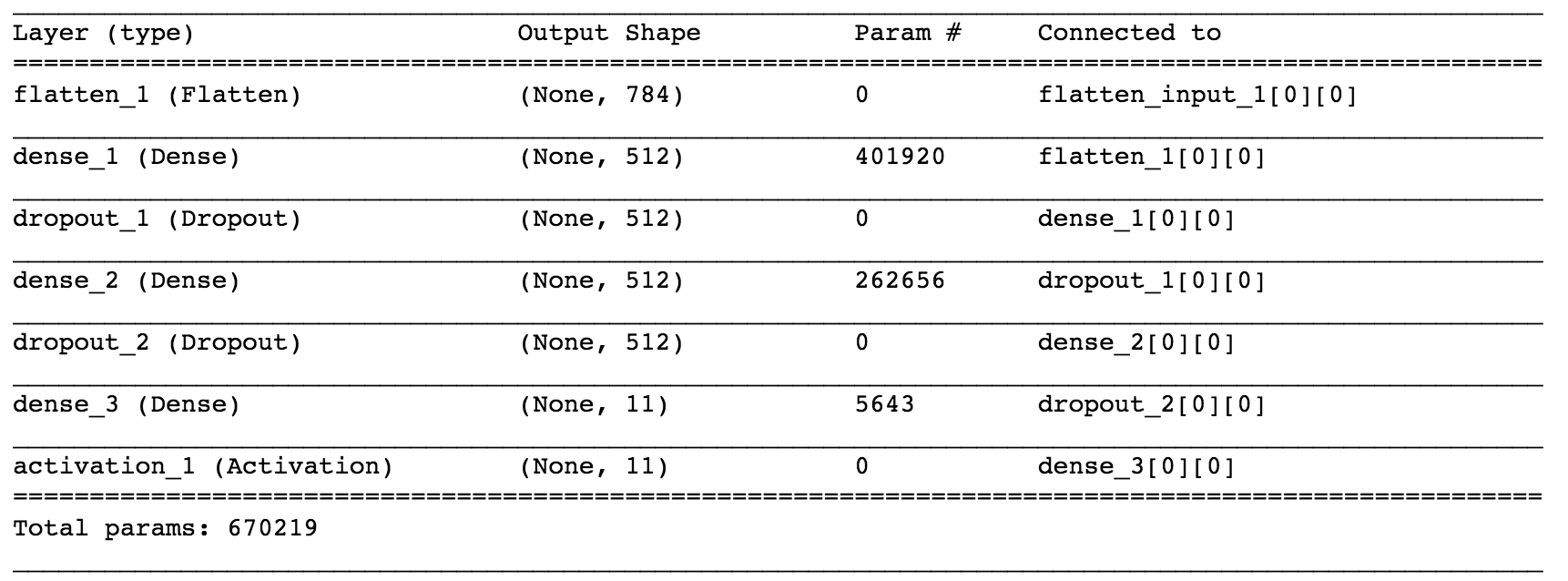
有了图像生成器之后我们就可以搭建我们的模型了,由于我们的模型结构十分简单784->512->512->11,再加上人性化的keras, 不出20行就可以搞定。
1 |
|
而且我们也可以通过代码清晰的看到我们的网络结构。
只需要训练10代,valid accuracy 就可以达到95%以上。
6.使用模型进行预测
最后,使用模型进行预测也是很重要的部分。我们输入的是一张含有数字的普通图片,我们需要将图片转灰度,自适应二值化,提取轮廓,寻找最小矩形边界,判断是否满足预设条件,如宽、高,宽高比。将满足条件的图片缩放至最大边长为28的小图,然后将其放入一个28*28的白色图像的中心位置。将处理好的图片送入模型中运算,得到识别的结果。

我们可以将我们训练好的模型应用到网页端或者某个app中。印刷数字识别的应用是非常广泛的,比如我们可以用它来识别车牌号,门牌号,快递单号(虽然通常的方法是扫描条形码😢)等。
我们的应用方法是将这个模型嵌入到了微信后台中,你可以在后台中回复一张图片,由于我们的模型简单,预处理方法也较为简单,所以发送的图片像素不要过大或者过小,白底黑字效果较好。可以尝试保存下面两张图的原图进行测试,发送时记得点预览并选择原图发送。


🔗完整的代码戳GitHub即可下载。
🔗主要包含两部分: